
Author: Scott Pletcher
Zero Trust Architectures: Refactoring ShowerThoughts(tm)
Authors Note: Personally, the term “cyber” or “cybersecurity” makes me cringe–can’t stand it…so let’s see if I can avoid it….much to the dismay of my SEO colleagues who insist it will get me way more clicks.
SEO Person’s Note: Bollocks! Give me those sweet, sweet clicks! Cyber-up kids!)
Cyber, Cyber, CYBER!
Those of us in the IT industry have long known the risks and potential potholes around lax or flawed security. We do what we can to make ourselves a “hard target”–opting for pfSense over the cheap ISP router, choosing Yubikeys for GPG and SSH, gently reminding our beloved family members not to click on that Nigerian Prince’s email.
But security is a team sport. It requires both our diligence and those of the service providers as well–and just like the general population, some service providers are more security-conscious than others. Criminals have followed the money right into a thriving ransomware and blackmail industry. Computer surveillance, espionage, and outright sabotage (such as Stuxnet) have become part and parcel of modern spycraft. Organizations and governments are clearly starting to wake up to what we “security nerds” have known for ages.
On May 12, 2021, US president Joe Biden signed an executive order laying out some quite extensive requirements for federal agencies around improving their information security posture. Among the requirements, agencies are now required to adhere to Zero Trust Architecture. (Note that this was not a surprise announcement…agencies had been urged to implement such measures for over a decade.) While there are many adaptions and commercializations of zero trust principles from consulting firms and software vendors, the National Institute of Standards and Technology (NIST) Special Publication 800-207 is considered the most agnostic.
The core idea behind Zero Trust is the realization that we don’t live in walled gardens anymore. Our apps are interconnected and have dozens of parts and pieces which all work together. This is a natural evolution as we moved from monolithic architectures into more specialized components and decentralized designs. In the days of old, we could just keep our computers locked up in a data center. The data lived in the data center, and we were only provided a window into that data via our green screen 3270 terminals.
Now, our data and applications are scattered far and wide among digital devices of all kinds. There’s no way this genie is going back in the bottle and it’s just not feasible to build fences around all our IT assets as we did in the old days. This acknowledgment of interconnectedness leads us to focus on the people, assets, and behaviors more so than trying to build higher fences.
Within the walled garden paradigm, we were able to trust those other actors and systems already inside the garden because they had already been vetted at the entrance, so to speak. Zero trust asks us to suspend the idea that everyone has been pre-vetted, in essence demanding proof of legitimacy with every interaction. This goes for resources as well as people. Another component of Zero Trust is compartmentalization. Compartmentalization is a way to help contain potential security threats by allowing parts of the application to only talk with those other resources to which they need to talk. We can minimize the room to roam should a bad actor get access to some server along our application chain–or better yet, replace the server altogether with managed services.
Being suspicious of each system component is only part of the plan. We should also remove opportunities for shenanigans that were possible in a more dynamic way. The “principle of least privilege” tries to make sure access is only as much as someone or something needs, but historically this was based on the high water mark of the most access needed regardless if that access was only used occasionally. Zero trust also means that we should be smarter in our access and provide the right access only at the right times. We can also learn from how people use our application and should be able to identify activities that might be abnormal–all consolidated into a single pane of glass.
Now, there are lots more to zero trust architectures but what I thought I’d do in this series is to illustrate by example how one might transition a “traditional” three tier web application to something closer to zero trust. Of course, you could go much farther than I did and perhaps that’s a good learning project–see how much you can apply zero trust principles to our sample application. Zero trust doesn’t require cloud resources but all the major cloud providers have spent lots of energy and money building out some pretty robust tools. In this walk-through, I’m going to be using features on AWS but you could do something similar using any major cloud provider.
The Scenario
One day, we had one of those shower thoughts…you know…those ideas that come to you spontaneously…just a pure stroke of genius. What if we built a service that allowed people to save their Shower Thoughts? After a weekend coding fest fueled by coffee and dub-step, we hacked together a three tier application that did just that… Behold! ShowerThoughts Depot(tm)!
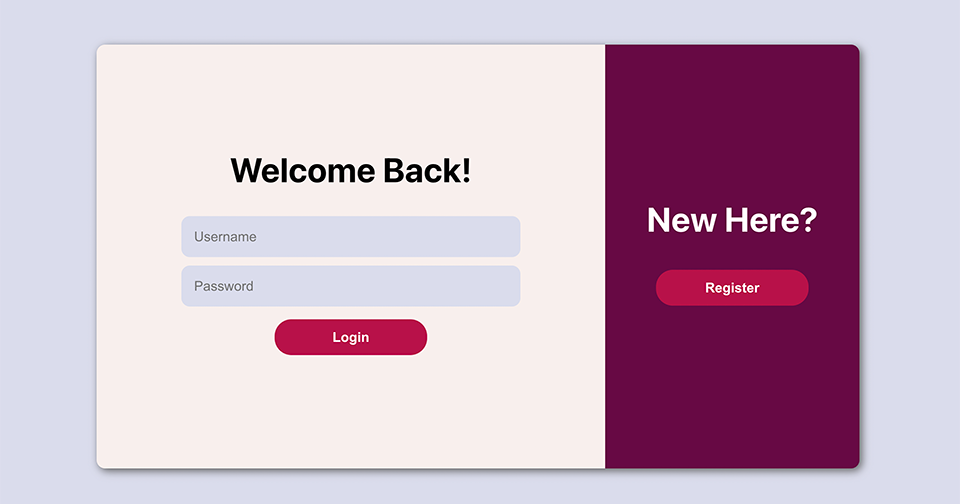
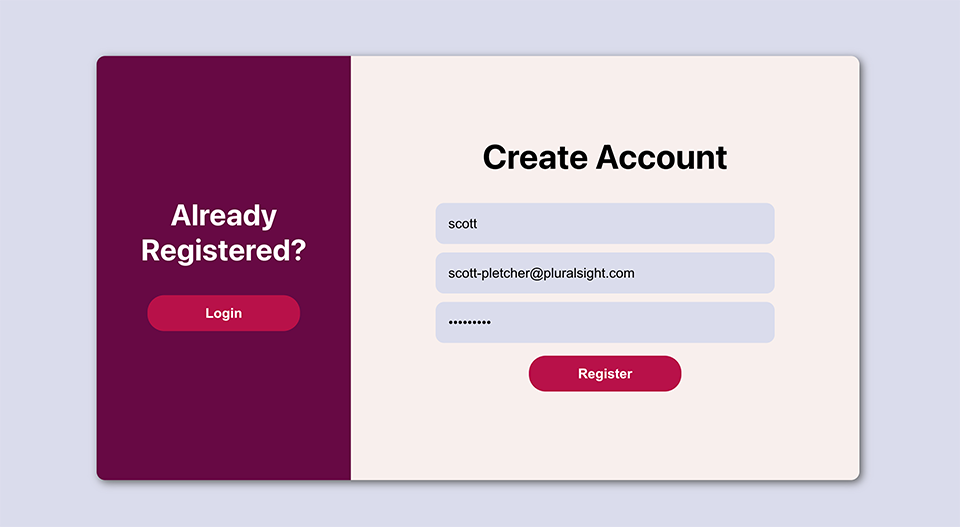
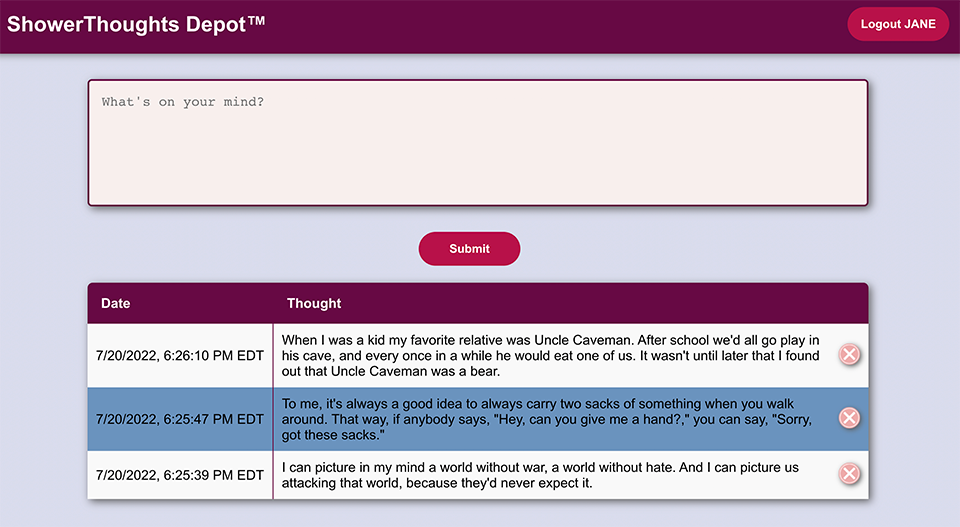
Now, just a note up front… Because I love Open Source, I’ve decided open source this wonderful application on my Github repo instead of cashing in on the sure thing cash cow that I could have sold to Meta, Google, or Amazon for BIG $$$. Never mind that it was almost entirely written by Github CoPilot…(tab) (tab) (tab)
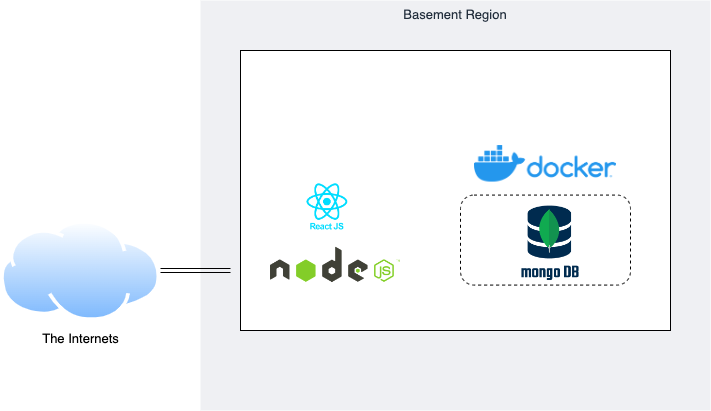
We’re using a docker-based MongoDB instance as our persistent data store, Node JS and Express for our service layer, then React for our web frontend. Our service layer API has three routes: Users, Authorization and Thoughts. Users handle our user account management, Auth handles the login process and generating JSON Web Tokens, and Thoughts takes care of our CRUD operations for our Shower Thoughts. We also have a separate middleware portion that reads and decodes our JWTs for our API calls. All of this is hosted on a single Ubuntu 20.04 server in our basement exposed to the internet via our Linksys router’s DMZ feature.
Hip to the Hype
Recently, our Shower Thoughts app has been getting lots of press lately, and the usage has spiked. With more users comes more genius ideas, and we begin to realize those genius ideas might be the target of some nefarious characters looking to cash in. As we’ve also been hearing lots about Zero Trust Architectures, we figure this is also a prime time to refactor into a more secure and resilient architecture anyway.
Feel free to take this example app as a starting point and try to refactor–there are lots of options here, and I’m going to share what I did. By no means is this a reference architecture of good app design or Zero Trust Architectures and one could go much further than I did to optimize and lock down the app. I’m just sharing how I approached this task and my learnings along the way.
For my refactor design, I’m going to do the following:
- 1. Implement a more robust and complete user management system with MFA capabilities
- 2. Build out some compartmentalization for the various layers.
- 3. Segment out some of the parts to scalable managed services.
- 4. Build firewalls and shields around our public-facing portions.
- 5. Intelligently log and monitor all the activity around our app.
Because this series is about the evolution of an application, I’ve created branches for each step of our evolution in the Github repo. This provides the snapshot of the code-based components along the way. One thing you’ll notice is that by adding in managed services, our codebase gets simpler and more streamlined…that a win!
New User management
In the olden days, each application had to maintain its own set of users, password validation methods, and roles. Things got a little better with the advent of LDAP and Microsoft’s Active Directory, but consolidated and federated user authorization and authentication are still a challenge. It makes perfect sense–have one source of truth for user data versus a bunch localized and maintained in their own way. However, integration into these services wasn’t always very easy. Fortunately, that’s changed, and authentication and authorization services like Auth0 and Okta base their business model around this one-login-shop idea.
AWS also has its own variety of an identity store called Amazon Cognito. Its pretty full featured and supports all the common interoperability standards and federation with the likes of Apple, Google, Facebook and…of course…Amazon. Cognito handles authentication and authorization–which are two different things. Authentication is making sure that you are who you say you are. Common methods for this are passwords, multi-factor tokens, hardware keys and such.
Authorization determines what stuff you have access to do–such as whether you can change records in a database or if you have admin rights. With Cognito, you can have your users authenticate via a variety of means and then have them assume roles which grant them permission to other AWS services via IAM–which is pretty useful indeed. But, to keep our scenario simple, I’m just going to create a user identity store that Cognito calls a User Pool. You have plenty of user attributes which you can track, and add custom ones if you want, but we’ll just use username, password and email for our user pool.
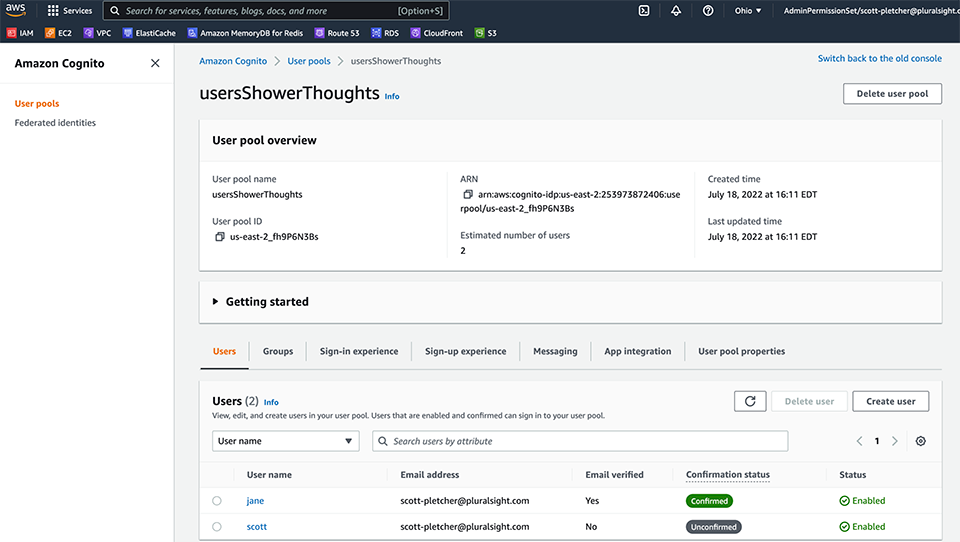
With this one User Pool, we can support many different apps. Cognito is built primarily with mobile and web development in mind, so there are handy SDKs for all the commonly used frameworks. We’ll create and copy our client ID and user pool as we’ll need to pass that into our call to the Cognito method. Just as in our original starting point app, we’ll just continue to use JSON Web Tokens as our authorization means. Upon login, we pass in the username and password to the Cognito verification method. The SDK handles validating the credentials, and if we’re good, we get an JWT which we’re stashing in our browser local storage. We’re going to include that token in the web service calls we make back to the server.
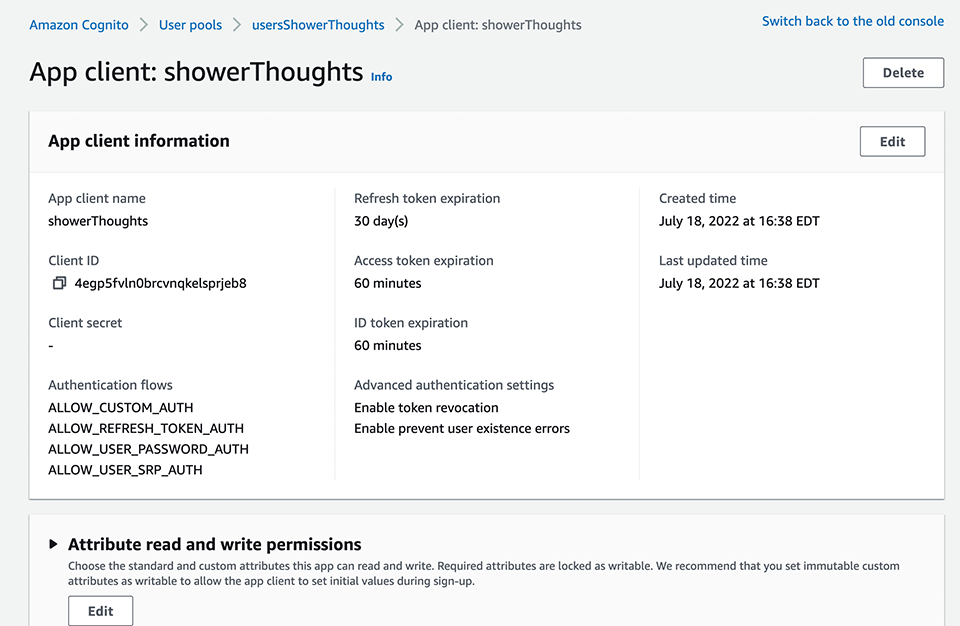
Now, on the server side (our Express app), we also implement a bit of Cognito via the SDK that can help us verify and decode that JWT. It first reaches out to the User Pool to get the public key, then it decodes the token. (Note that in using the method I am, the server does need internet access to reach back to the public endpoint for Cognito. As of this writing, Cognito does not support AWS PrivateLink.) The SDK checks to see if the token is still valid and extracts the username to which the token was issued.
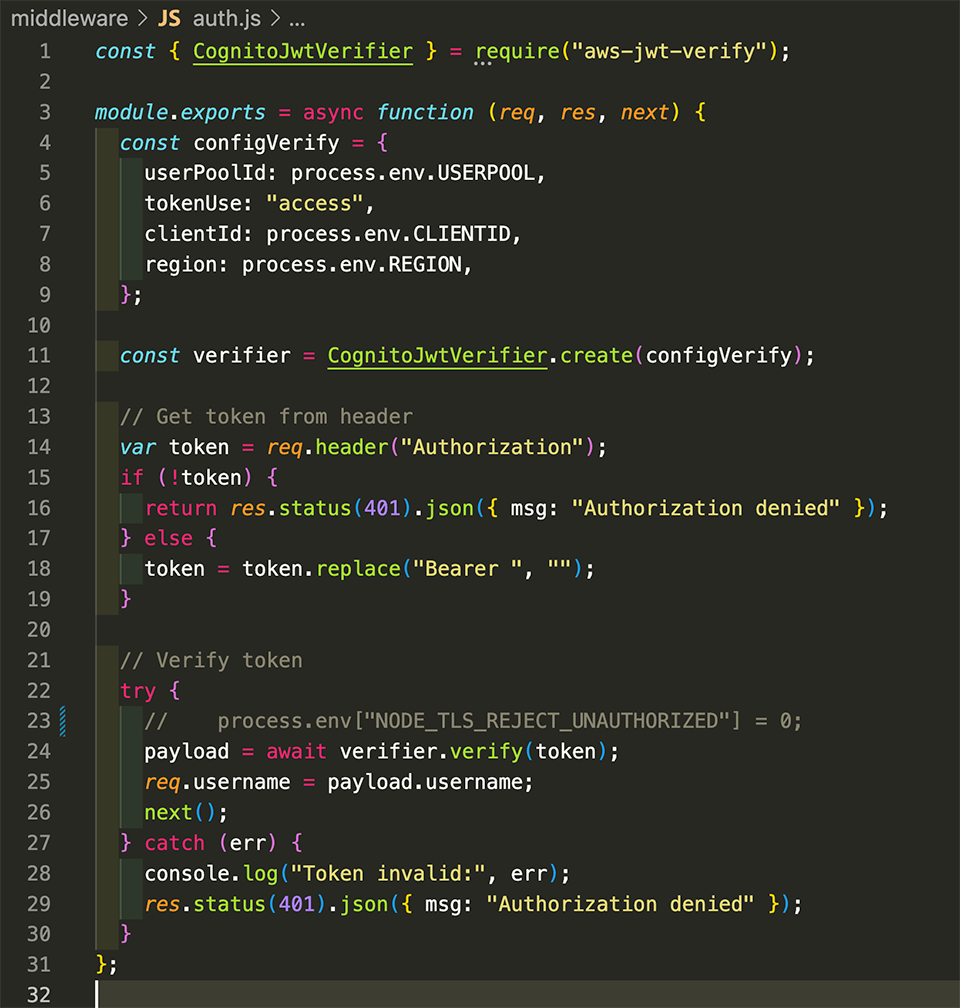
We can then, in our thoughts.js code, compare that token username to the username that was programmatically included in the web service call to give us a very rudimentary authorization method. In essence, if you try to make a change for a user other than what your token says, you’ll be rejected. And, (hopefully) you won’t be able to get your hands on another user’s token. This is a very simple authentication and authorization model but it works.
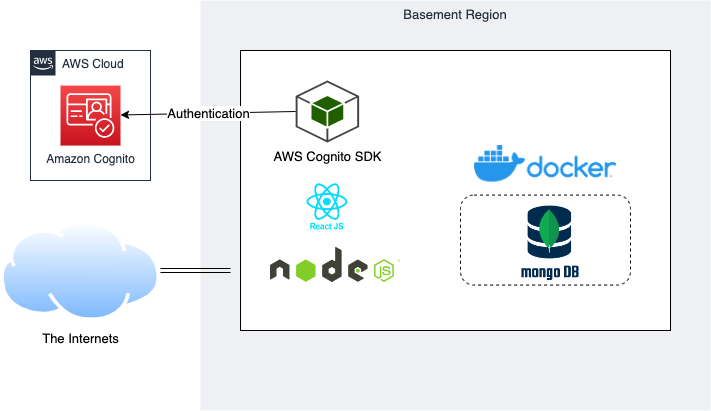
With that, we now have a full featured, extensible and scalable user identity management component for our application. And the best part…we get to retire those parts of our API that handled authentication and user management! Yay! In the next post, we’re going to design a network that helps us better compartmentalize our components, and we’ll move our datastore to a hosted service.