Author: Elton Stoneman
Monitoring is the first level of observability - providing insight into your applications so you can quickly identify and fix issues. A good monitoring solution shows you at a glance how hard your apps are working and how well they’re performing. The leading technologies in this space are Prometheus and Grafana, which work together to collect and visualize metrics from all parts of your application.
The modern monitoring stack
Monitoring used to be a simple problem - you needed to check the CPU, memory and disk of a fairly static set of servers. You’d install an agent on those machines which collected the data and pushed it to a centralized system. That system stored the metrics and provided the insight with dashboards and alerts. Then came containers and the cloud and those statically-driven systems didn’t make sense, because the world became dynamic. Now instead of running a handful of servers, you might be running dozens of VMs or hundreds of containers, scaling up and down automatically, and being replaced whenever updates are released.
In this world you need a monitoring system which is dynamic too, one which can discover new targets by itself and which has the flexibility to record and analyze any metrics which are important to you. That’s Prometheus, an open-source monitoring framework which is a CNCF project (the same foundation which stewards the Kubernetes project). Prometheus turns the collection process around - instead of servers running an agent to push data to a central server, your application components expose metrics in an HTTP endpoint and the central server pulls the data from the targets:
![Monitoring Containers (and Everything Else) - with Prometheus and Grafana][0]
This architecture makes metrics collection efficient and scalable, and it has the benefit of being centrally managed. You configure all aspects of metric collection in the Prometheus server, so if you want to change the frequency of collection, or add and remove targets, you can do that without any changes to your running systems. It also means you can run metric collection at different levels - you could have targets exposing the CPU and memory stats from servers, and more detailed stats showing you the disk read performance from SQL databases.
Prometheus pulls in all that metric data and stores it in a time-series database, so every item is stored with a timestamp recording when it was collected. That lets you query the current metrics and also find trends over time, which is what powers your application health dashboards. Query functionality is built into Prometheus, which runs an API server to process queries written in the Prometheus query language (PromQL). Prometheus is a complete monitoring framework, and it uses a generic metric format which is suitable for any component.
Getting Started with Prometheus introduces you to Prometheus and application monitoring, it’s part of the Event Monitoring and Alerting with Prometheus learning path on Pluralsight.
Application, runtime and system metrics
Adding Prometheus support to your applications means providing an HTTP endpoint which publishes metrics in the Prometheus format. Browse to the /metrics endpoint of an application and the response will look like this:
# HELP node_filefd_allocated File descriptor statistics: allocated.
# TYPE node_filefd_allocated gauge
node_filefd_allocated 1184
# HELP node_disk_io_time_seconds_total Total seconds spent doing I/Os.
# TYPE node_disk_io_time_seconds_total counter
node_disk_io_time_seconds_total{device="sda"} 104.296
This example shows two metrics - typically there will be tens or hundreds of metrics, but the format is always the same. The HELP line shows some user-friendly information telling you what the data means, the TYPE line tells you what type of data it is, and then you get the actual metric value. Metrics are always numeric values, and the simplest data types are gauges - they represent a single value which can go up or down, and counters which always increase (or stay the same).
These two samples are server-level metrics, they tell you how many files are currently open, and how long the machine has spent reading and writing from the disk. The values here are a snapshot - Prometheus would store these with a timestamp, and the next time it fetches them it will record the new values with another timestamp. If the number of open files dropped but the disk I/O increased hugely, that could indicate a problem and it would be easy to show that in a graph.
You should take away two important points from this example: metrics have metadata to describe themselves, and the same metric can report values for different items. Prometheus doesn’t need to know what data is coming from an endpoint, it just stores everything that comes in, so your components can publish the metrics which are important to you. And metrics can be striped - the disk I/O example has a single entry for the disk called sda - if you had multiple disks, the same metric would be repeated for each of them.
This flexibility lets you collect metrics at different levels of detail. System metrics will tell you if your infrastructure is getting saturated - when the CPU is maxing out or you’re running out of memory. Runtime metrics tell you how hard your application is working - everything from the number of CPU threads to the average response time for HTTP requests. You get all those for free with standard Prometheus components you can drop into your solution, and you can also record custom application metrics which tell you what your app is actually doing:
# HELP process_cpu_seconds_total Total user and system CPU time.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 384.23
# HELP worker_jobs_total Worker jobs handled
# TYPE worker_jobs_total counter
worker_jobs_total{status="processed"} 1570222
worker_jobs_total{status="failed"} 159665
This example is for a backend processing component. It uses a Prometheus client library to record a custom metric for how many jobs it has processed, including the total and the number of failures. That client library provides the HTTP endpoint and the standard CPU metrics. There are client libraries for all the main application platforms, which also give you detailed information about the runtime - for a .NET app you’ll see metrics for garbage collection, and for a Go app you’ll see the number of active Goroutines.
Collecting metrics with Prometheus
Custom metric collection needs some development work to record the detailed metrics about what your app is doing. The code for that is typically very simple - here’s the .NET implementation for the jobs processed metric:
// create the metric - you only need to do this once:
private static readonly Counter _JobCounter = Metrics.CreateCounter("worker_jobs_total", "Worker jobs handled", "status");
// use the metric during processing:
var result = ProcessJob();
_JobCounter.Labels("processed").Inc();
if (result.Status) > 0
{
_JobCounter.Labels("failed").Inc();
}
Here we create the counter metric when the application starts up - the creation code includes the metric type and the help text you see in the HTTP endpoint. For every job we increment the counter with the processed label, and if there’s a problem we also increment the failed label (there’s no need to record the number of successes, because we can calculate that from the other two).
For other components there are pre-built Prometheus exporters, which give you detailed metrics for a wide range of systems - everything from MySQL and Elasticsearch, to Jenkins and even third-party apps like Pingdom. You run those alongside your other components to give you a full suite of metrics at every level.
Exporters are integrations that plug Prometheus into your application architecture, and there are also integrations for the platform you’re using to run applications. These are for service discovery. You can configure Prometheus to use your platform APIs - which could be the Kubernetes API if you’re running in containers, or the Azure APIs if you’re running in the cloud - and Prometheus will query the platform to find all the metric targets. This example shows Prometheus configured to find targets in Kubernetes, using labels so only certain objects are included:
![Monitoring Containers (and Everything Else) - with Prometheus and Grafana][1]
This is how you run Prometheus in production, and it means the monitoring system reacts to any changes in the environment. When you scale up to add more servers, or replace containers as part of an update, the new components are automatically found and added to the collection list. Service discovery can be static too - using DNS or even a fixed list of IP addresses - and you can combine multiple discovery sources, so Prometheus can be the single monitoring component for old and new applications.
Visualizing metric data with Grafana
The Prometheus server has a simple web UI for querying data and building graphs, but its not a full dashboarding solution - for that you use Grafana. This is where you’ll see the real value of storing data in a time-series database, displaying the current state of your metrics and trends over time in a single view:
![Monitoring Containers (and Everything Else) - with Prometheus and Grafana][2]
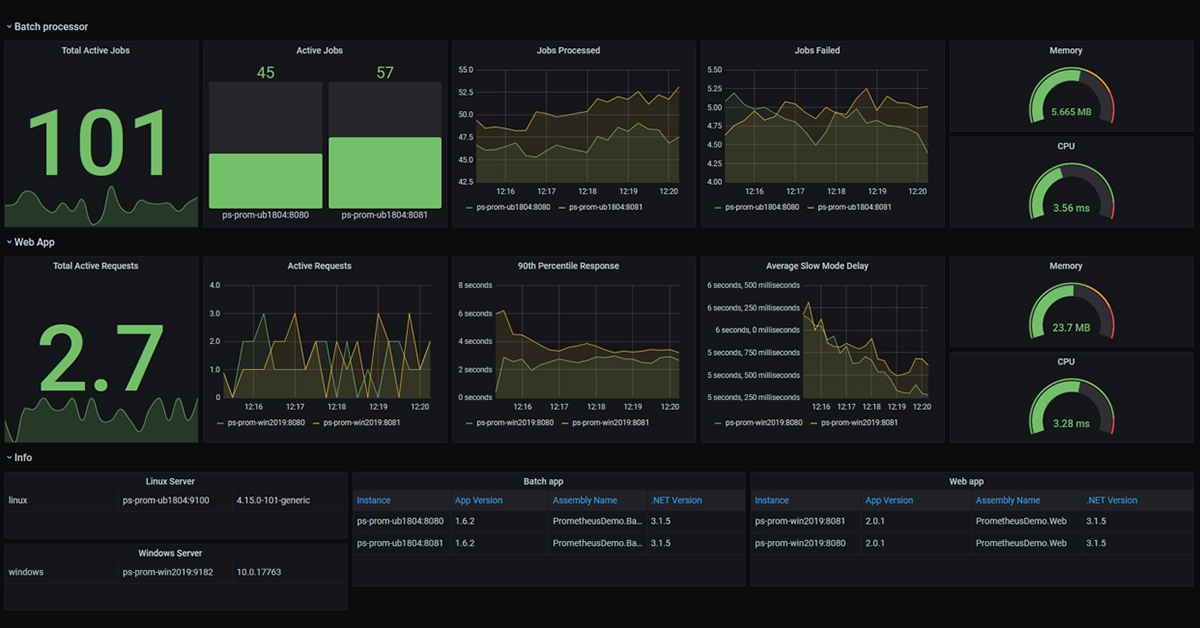
This is a sample dashboard for a simple demo app, but it’s worth digging in to what it shows so you can see the full potential of the monitoring solution:
- the top row shows metrics for a background job processor, which runs across two Linux servers;
- for the job processor we can see the total active jobs, together with the processed and failed counts, split between the servers;
- the middle row shows metrics for a web application, which runs across two Windows servers;
- the web metrics show current active requests, response times and a measure of processing time;
- the gauges show the average memory and CPU usages for the job processor and web servers;
- the bottom row shows information about the servers and application components, including version numbers.
There’s an awful lot of information there, but it’s presented in a clear and easy-to-read way. If the response time for the web site is trending upwards and the CPU gauge for the web servers is in the red, that gives you a hint that the servers are working too hard. You can set the time span for the dashboard, so you could load the data for your previous application release and see if the increased CPU is an issue introduced in the latest release.
Metrics in the observability stack
Metrics are only one part of observability. They power the dashboards that show the general health of your applications, and trigger alerts when things aren’t looking good. But Prometheus works by sampling your metrics endpoints, so it collects regular snapshots but doesn’t record every event that happens, and it doesn’t record all the data about events. Metrics will tell you that the number of 500 error responses from your web application has spiked, but it won’t necessarily tell you why.
The next level of detail is logging, where you do record all the detail you need for every event of interest. The modern observability stack includes centralized logging, using technologies like the ELK stack (Elasticsearch, Logstash and Kibana). That gives you a single store for the logs from all parts of your application and the ability to search across them all. With Kibana you can search for a unique error code reported by an end-user and see all the logs surrounding it to help you track down the problem.
The final part of observability is distributed tracing, which helps you correlate multiple service calls that are all part of a single client request. Tracing lets you to identify the connections between components, and the time taken for each part of the call chain. Tools like Jaeger help you visualize the service graph in your application and identify slow-running components. Metrics, logging and tracing give you full insight into your applications and the most popular tools are all open-source software, working with standards like OpenTelemetry.