
Author: Nicholas Russo
DevOps isn’t a new concept, and you’ve likely heard the term before. Most of the technical discussions, training material and real-life applications of DevOps principles revolve around software development and application deployment. Organizations want to deliver their applications faster, at lower cost and with higher quality. DevOps enables these organizations to do just that.
What about the rest of us who don’t develop applications for a living? This blog post is for all the network engineers, system administrators and information security professionals who also want to do their jobs faster, at lower cost and with higher quality. Many of the software-oriented DevOps principles apply to IT operations with a few minor adjustments.
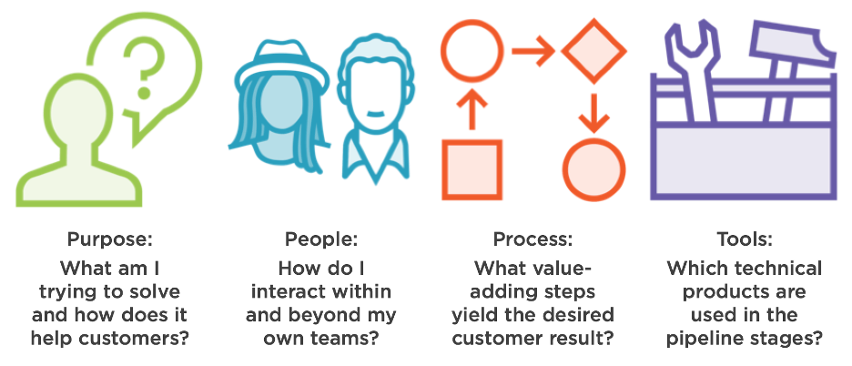
The four pillars of DevOps
If you ask your favorite search engine about “DevOps principles,” you’ll find any number of answers, so I won’t attempt to offer pseudo-authoritative guidance on precisely what counts as a “DevOps principle.” Instead, let’s elevate the discourse by focusing on what I call the four pillars of DevOps because they are broad, timeless and indisputable.
1. Purpose: Identify the problem to be solved and any constraints that apply. Far too often, I’ve consulted for organizations that trip over their own shoelaces trying to “do DevOps” by adopting buzzwords and purchasing tools without a clear picture (or “target condition”) on their end state. I even worked with a client who claimed to have productized DevOps into a laptop, whatever that means. This customer remains without a clear DevOps strategy today, years later.
2. People: The human aspect of DevOps has a few dimensions. At the top level, software developers and IT operators need to cooperate better: Blameless post-mortem analyses after outages; construction of test, development and production environments consistent with the requirements of the developers (and the business); and rapidly communicating real-time issues for analysis, repair and patch deployment.
At a lower level, consider the human interactions within each group. The same behaviors just described can be applied to internal projects, such as team-level code reviews or IT infrastructure upgrades.
3. Process: At the heart of productivity improvement methodologies like Lean and the Theory of Constraints (TOC) lies the pursuit of the perfect process. The idea is to arrange the value-adding steps in the proper sequence to yield the desired result as specified by the customer. Non-value adding steps, such as transportation, storage and waiting in queues should be minimized. For both software developers and IT operators, this usually involves a continuous integration/continuous deployment (CI/CD) pipeline to automatically test, package and deploy applications. We’ll dig into this soon.
4. Tools: This is self-explanatory. You can’t implement DevOps without the right tools to accomplish the myriad of tasks involved. This tends to involve a source code repository, a pipeline framework with customizable stages, a notification or feedback system, and a monitoring system for metrics/telemetry collection. Pluralsight has a wide selection of courses covering various DevOps solutions ranging from cloud-based software-as-a-service offerings to traditional on-premises products.
Some organizations make the mistake of diving headfirst into learning about DevOps tools without having invested any time reviewing their business purpose, coaching their people or developing their processes. This is especially tempting for technologists who want to immediately get their hands dirty with the DevOps product du jour.
The diagram below summarizes these four pillars just described. Feel free to save a copy on your workstation for quick reference.
Employing CI/CD as an IT operator
I want to zoom into “process” more than anything else because this is where most clients struggle. Specifically, I want to discuss how an IT operator might constructively employ CI/CD, and how it compares to a software developer’s pipeline. First, consider the diagram below, which illustrates a nondescript application testing and deployment process:
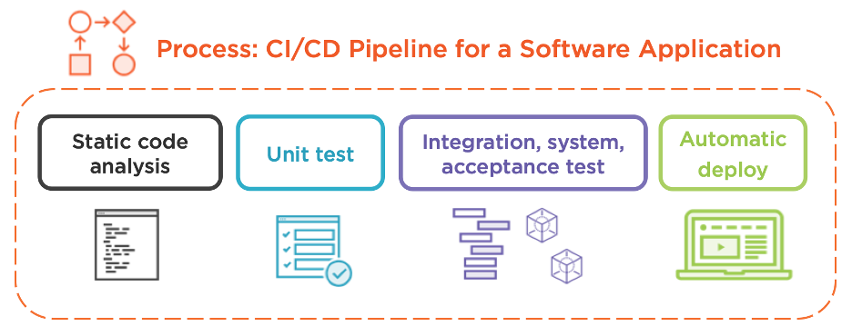
The pipeline starts when a developer commits code to the centralized source code repository (in the world of Git, a “git push” action). The communication between the pipeline service and the repository often relies on a webhook notification but could use a custom integration, depending on the products. When it comes to the test stage, a good first step is to perform static code analysis and refinement. This phase often includes the following:
- 1. Linting: Checking for syntax errors and styling transgressions
- 2. Security scanning: Looking for exploits and insecure code
- 3. Code formatting: Automatically changing the code to comply with standards and conventions
The beauty of static code analysis is that it doesn’t run the source code. It’s like holding a piece of paper at arm’s length and visually scanning for any obvious problems. As such, it finishes quickly and is low risk because any exploits in the code won’t be triggered.
Next comes unit testing. It tests the individual components of a project, such as functions and classes (language-dependent, of course). Developers typically create these tests by passing in a static input then testing for a static output. For example, if you’ve written a function named “square(x)” that multiplies the integer “x” by itself, passing in a 2 should yield a 4. Passing in a 3 should yield a 9, and so on. Testing invalid inputs, like strings, is a good way to increase test coverage to ensure your individual code components handle errors correctly. Unit testing tends to run very fast because the entire application doesn’t need to be deployed, just small parts of it in isolation.
The tests get more and more involved as the pipeline continues, and in the interest of time, I won’t dissect each one. Some pipelines have a dedicated integration testing phase whereby a small set of units (functions, classes, etc.) are tested in unison. Some pipelines may opt to skip this step and go straight to system testing that deploys the entire application to ensure it is technically functional. Some pipelines append user acceptance testing once the system is validated to measure the user experience, answering questions like “Does the Add To Cart button work?” and “Does the web page load fast enough?”
The final step involves deploying the application to production. After all, once the automated testing is complete, the application should be ready for primetime! There’s a ton more detail on the topic of automated application deployment, but let’s get back to IT operations.
How much of this CI/CD pipeline is relevant for infrastructure engineers?
Surprisingly, most of it. Starting with static code analysis, this is wholly transferable to DevOps in an IT operations context. For example, if you’ve written some Python scripts to manage your network infrastructure, you can use pylint to lint your code, bandit to scan for security holes, and black to automatically format it to the PEP-8 standard. Other tools exist, but I wanted to provide examples of tools I’ve been using successfully for years.
Now, consider unit testing. The pipeline doesn’t communicate with live devices at this point, but we can certainly test the functionality in a vacuum using static inputs and outputs. This is sometimes called “mocking.” we can simulate the behavior of a network device for the purpose of testing our functions. In the context of Python, I find this particularly useful for testing utility functions, such as parsers, by fabricating plain-text devices outputs and feeding them into the parsers for evaluation.
For system-level testing, the pipeline will spin up virtual devices that represent your infrastructure. If you’re a server administrator, a few Docker containers might be adequate, allowing your automation system to manage the configuration of the ephemeral test instance before attempting it on production devices. For networkers, consider spinning up a few virtual machines or cloud instances of the relevant devices and testing your scripts on those. I’ve personally used Cisco Modeling Labs (CML) and Amazon Web Services (AWS) for such testing.
Since IT operators aren’t deploying an application per se, what does the deployment phase look like? Remember, we’ve extensively tested our automation system using a live, simulated network. Assuming you trust your test coverage, this phase enables the pipeline to automatically run the automation scripts against the production network. This is known as “infrastructure as code” and is among the most powerful concepts in modern IT management. Rather than manually configuring network devices and dealing with the fallout from the inevitable typos that break business-critical applications, IT operators can “declare” their end state.
In small environments, this might be a YAML or JSON file that identifies the correct state that a certain device should be in, for example:
- Which VLANs should be on this switch?
- Which users should have sudo access on a given workstation?
- Which packages should be installed on this web server?
More complex environments may have a centralized database to store these values, like a single source of truth, but the concept is the same. Users can update the state declaration then initiate the CI/CD pipeline. This is commonly done using git push, just as it is in the software development world.
Examples
Below is a YAML-formatted example to manage Multi-protocol Label Switching (MPLS) route targets in a declarative manner. If a value is present in this file, the automation system ensures it is present on the managed device. If a value is absent from this file, the automation system ensures it is absent on the managed device. Simple and powerful!
vrfs:
- name: "FIRE"
description: "FIRE STATION"
rd: "65000:1"
route_import:
- "65000:1"
route_export:
- "65000:1"
- "65000:7"
- name: "CHEM"
description: "CHEMICAL ENGINEERING FIRM"
rd: "65000:2"
route_import:
- "65000:2"
- "65000:3"
- "65000:4"
route_export:
- "65000:2"
Below is a conceptual example of a GitLab-based CI/CD pipeline for a large customer project I recently completed. The task was to manage configurations and software versions on a particular brand of network device using infrastructure as code. This YAML file reads like English, and even if you don’t completely understand the syntax, this should provide a logical template for your own pipelines in the future. Notice that the names of the stages don’t perfectly align with the diagram and discussion from earlier. That’s okay! Fall back to your “purpose” and do what makes sense for your particular organization.
stages:
- lint
- unit
- dryrun
- prodrun
lint_job:
stage: lint
script:
- 'find . -name "*.yml" | xargs ansible-lint'
unit_job:
stage: unit
script:
- 'pytest –verbose test_parsers.py'
dryrun_job:
stage: dryrun
script:
- 'ansible-playbook deploy_testbed.yml'
- 'ansible-playbook update.yml --check'
prodrun_job:
stage: prodrun
script:
- 'ansible-playbook update.yml'
- 'ansible-playbook postdeploy_validate.yml'
I’ve updated our CI/CD pipeline diagram to better reflect an IT operations workflow related to network device management. The context and outcomes change, but the logical sequence does not.
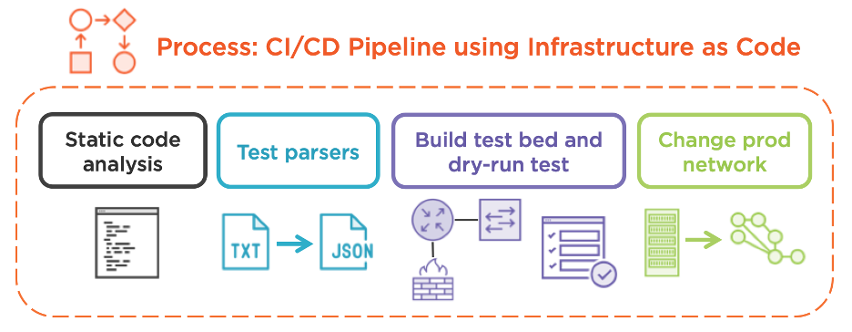
You might be wondering why I waited until the end of this blog to finally talk about DevOps for IT operations. That’s because it’s very similar to DevOps for software developers! The general concepts, such as the four pillars and the CI/CD phases, are directly comparable. You can leverage many of the same tools as well; I’ve personally used AWS CodePipeline, GitLab CI and Travis CI for several real-world projects, both for software applications and IT operations. The main difference is that the scope and purpose of testing and deployment changes.
If you’d like to learn more about DevOps and infrastructure as code, consider watching my associate and professional Cisco DevNet learning paths on Pluralsight. I’ve also demonstrated specific examples of linting and unit testing with Ansible and Python network automation courses as well. Enjoy!