
Author: Elton Stoneman
Site Reliability Engineering (SRE) is the practice of managing systems through software - automating operations tasks, designing systems to scale automatically and self-heal, and approaching production issues with a structured framework.
It’s how Google manage their critical systems, and it’s now widespread in the industry as an alternative to both DevOps and the traditional Dev-versus-Ops structure. SRE and DevOps have much in common, but in digital transformations SRE can be less disruptive and easier to implement gradually.
The Reality of DevOps Transformations
The fundamental conflict in software delivery is so profound that’s it’s amazing any software gets delivered at all. The conflict is built into the structure and reward of the IT department in most organizations: development teams build new products and features, and ops teams release and manage the products. Dev teams are measured on how many features they deliver, while ops teams are measured on how rarely things break.
And that’s the problem - the best way not to break things is not to make any changes, so ops are incentivised against new releases:
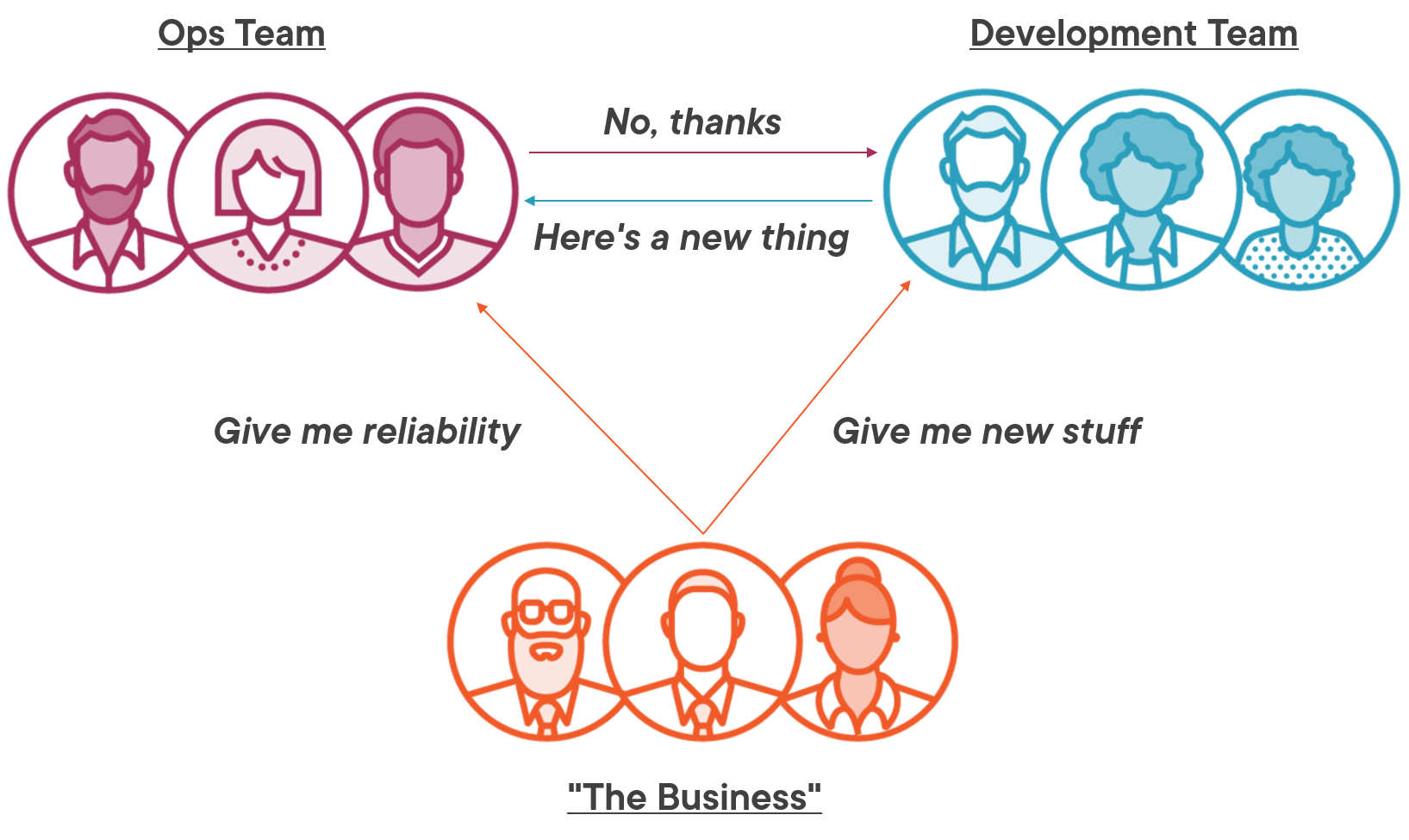
DevOps explicitly addresses that by combining dev and ops functions in a single team. Each product is owned by a cross-functional team which manages the complete lifecycle, from development to delivery and maintenance. An established DevOps team looks like this:
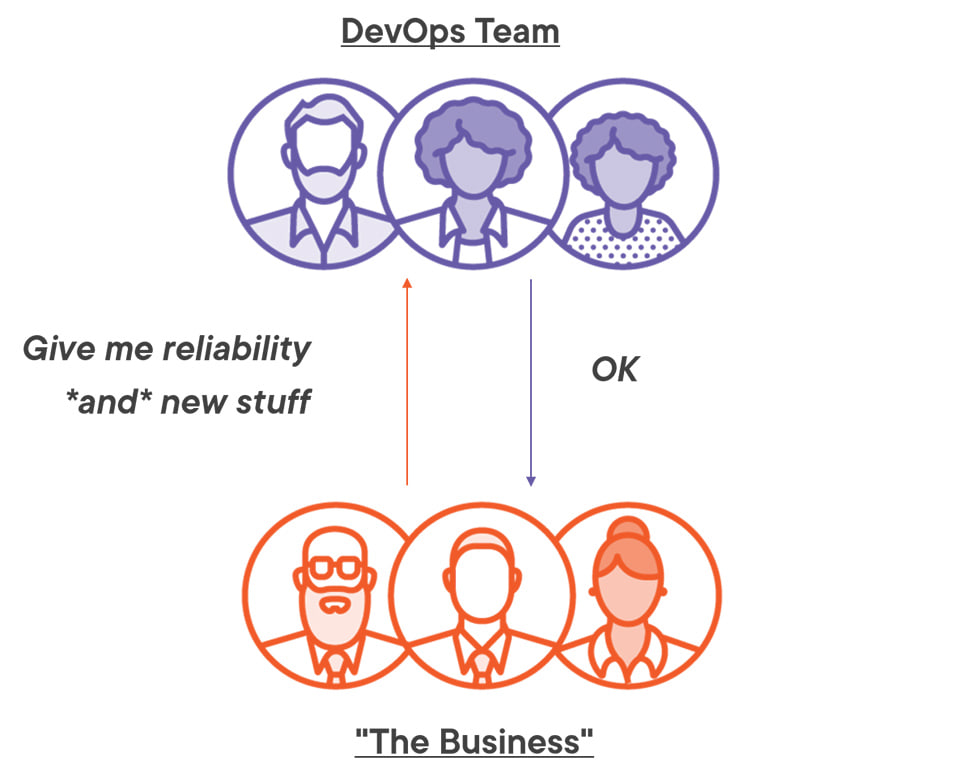
If you’ve worked in a DevOps environment you’ll know that it’s a highly effective model, where frequent high-quality releases are the norm and all parties share a sense of joint ownership. It’s the natural approach for startups which are small enough to have a single delivery team, and it’s the envy of older organizations with established - and less effective - dev and ops functions.
Established organizations transitioning to DevOps usually merge together dev and ops people into new product teams. It’s a disruptive process and it can take a long time for those new teams to be effective. And during that transition period the team may be even less productive than under the previous model:
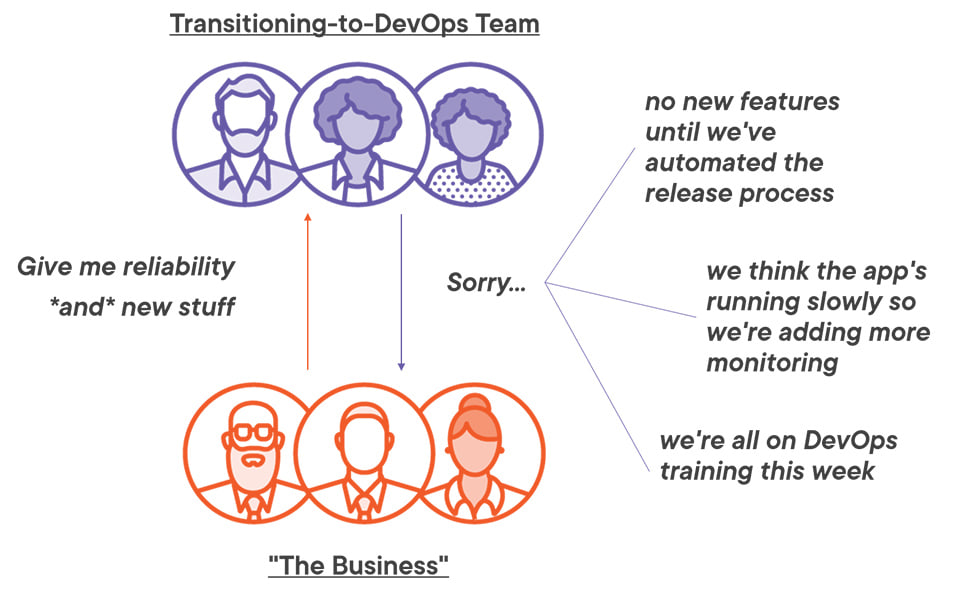
That’s one reason why SRE is more attractive in digital transformation projects - there’s still a split between the development and delivery functions, but SRE changes the way teams work and how they work together.
SRE Fundamentals
SRE teams manage systems through engineering - they’ll write software to automate repetitive tasks, to add monitoring dashboards, and to improve the reliability or scalability of applications. SRE teams work closely with dev teams, helping out with architecture decisions, understanding the features coming in the next delivery and embedding engineers in the product team if there are quality issues.
Organizations may have an SRE team for each product, or a team for each core product, or a single SRE team to oversee critical, shared systems. The implementation of SRE can be moulded to fit the way your organization works, guided by the core practices in the original Site Reliability Engineering textbook. That’s a proscriptive introduction to SRE which helps you understand how the practices work and how you can adopt them.
SRE practices broadly fit into three areas:
eliminating toil - reducing or removing repetitive manual work so the SRE team can focus on high-value work
managing risk - understanding that software delivery is inherently risky, with tools for measuring and limiting risk
handling failure - frameworks for dealing with production issues and learning from them.
Site Reliability Engineering (SRE): The Big Picture on Pluralsight covers all the details of SRE
Eliminating Toil
Ops log, day 471: web server ran out of memory. Logged on, restarted the web server process, logged off. Updated the ticket. Will need to do this again on Wednesday.
This is toil: mundane, low-value, repetitive work which can be automated. No-one really wants that to be their job, but if an application has a memory leak then what are the options? In the SRE world an engineer could script the restart process and run it on a scheduled job at a time when usage is low. Or move the application to containers with a platform like Kubernetes to monitor and restart the application automatically. Or work with the product team to find and fix the memory leaks.
Those options range from a band-aid to a permanent fix, with different levels of investment and risk. But they all remove the problem of an engineer manually restarting the application every time it runs out of memory. That frees up time which was lost to toil and makes it available for more impactful and rewarding work.
Eliminating toil altogether may not be realistic, but SRE guarantees that engineers won’t have all their time swallowed up with repetitive work by setting a cap on toil time:
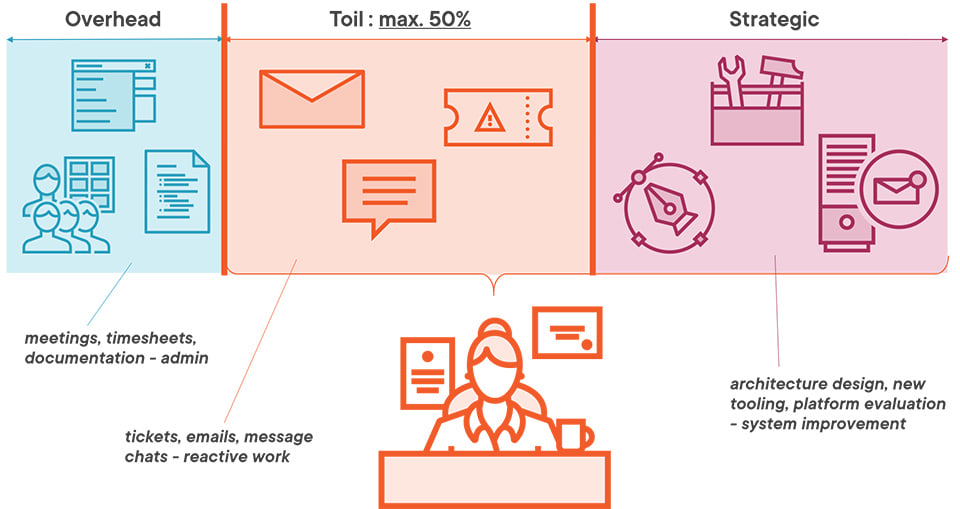
In Google toil is capped at a maximum of 50% of SRE time. The percentage varies between organizations - but this is an explicit guarantee. It’s part of the job description and it’s publicly known, so dev teams and product owners are aware that SREs will not spend all their time on toil.
That leaves engineers with time for strategic work which improves the design and scalability of the product, or the efficiency of the alerting system or the speed of the CI/CD pipeline. Those are high-value long-lasting improvements which could be used for other projects too, and that’s a better use of time.
Managing Risk
System failures happen most often when there’s a new release or a configuration change. Leaving your systems untouched will definitely help your uptime, but product owners will want the odd new feature and those monthly security patches are probably a good idea too. SRE provides an explicit measure of deployment risk: the error budget.
Error budgets state how long a system can be in a sub-optimal state over a given period. That’s measured in terms of Service Level Objectives (SLOs) which are metrics that gauge the health of the system from a user-focused perspective. You might use web server response times as a metric, a measure of performance which is much more meaningful than the amount of CPU your web servers are using.
The SLO for the homepage might be for 99.9% of requests to get a response within 2 seconds. That gives an error budget of 0.1% (100% minus the SLO), which means over a 28-day period you have 41 minutes where responses could take longer than 2 seconds:

In a healthy system which doesn’t have recurring problems, the error budget is your deployment window. It specifies an allowance of time where the system is underperforming but that’s OK. Your release process might reduce capacity during the rollout, or you might need to reboot servers, or you might spend that time fixing a configuration issue.
The goal of the error budget is to agree that amount between the product owners, the dev team and the SREs. It’s a great way of arguing against more nines - if the business want to move this SLO from 99.9% to 99.99% that means the error budget is only 4 minutes over 28 days. That smaller window might mean one release instead of 10, and that’s a discussion that can be had, with everyone aware of what the measurement is and what the extra availability will cost.
What happens if the error budget is breached? That’s also agreed and explicitly stated in the Error Budget Policy. Typically the policy says that if the error budget is exceeded then there will be no more releases in the period - or only critical security patches.
Handling Failure
Failures will still happen, and diagnosing exciting new breakages is a part of the job which some SREs enjoy most. Being on call is a high-pressure, high-visibility role, and SRE has defined practices to help reduce stress and get to a quicker resolution.
The first of those is an incident management process with separate and clearly defined roles. Every production incident has an Incident Commander, a Communications Lead and an Ops Lead:
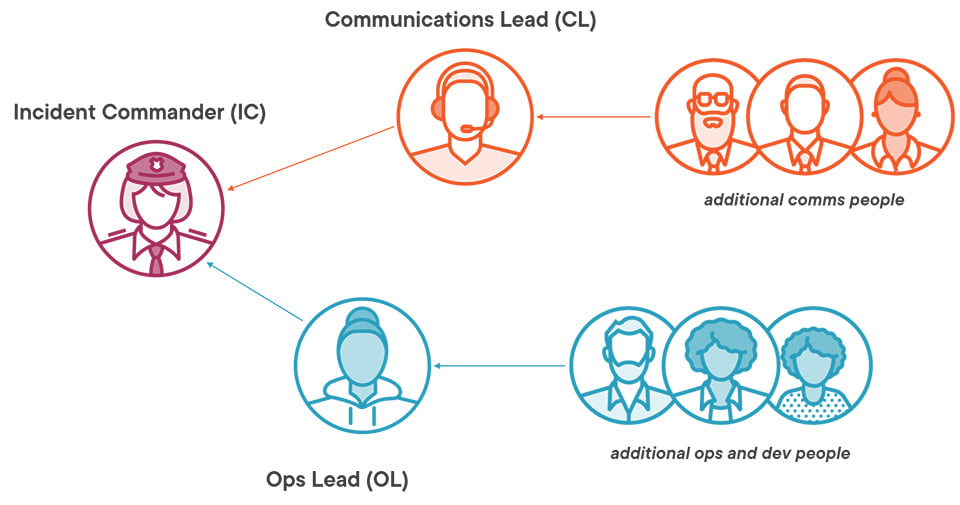
The Incident Commander manages the whole thing, they’re the person who finds more people when they’re needed, leads discussions and makes decisions. That removes the ownership role from the Ops Lead who is focused on dealing with and resolving the incident - usually with help from other SREs or the product dev team. And both those roles are separate from the Communications Lead, who publishes the status of the incident and is the point of contact for the business (possibly with help from other team members).
Clearing away the management and communication roles gives the Ops Lead a clear space to work through the incident. SRE also has guidance on effectively managing incidents, starting with a triage stage where the goal is to remediate the problem as quickly as possible, and get the system back into a functioning state. A clear incident model helps if another Ops Lead needs to take over - the current status will be well documented and the next steps will be a standard part of the process.
Once the incident is resolved the team put together a postmortem document, which details the nature of the problem, the steps taken to fix it, system changes which are needed for a permanent solution, and any lessons learned in the investigation. They follow a standard format and they should be published across the whole organization:
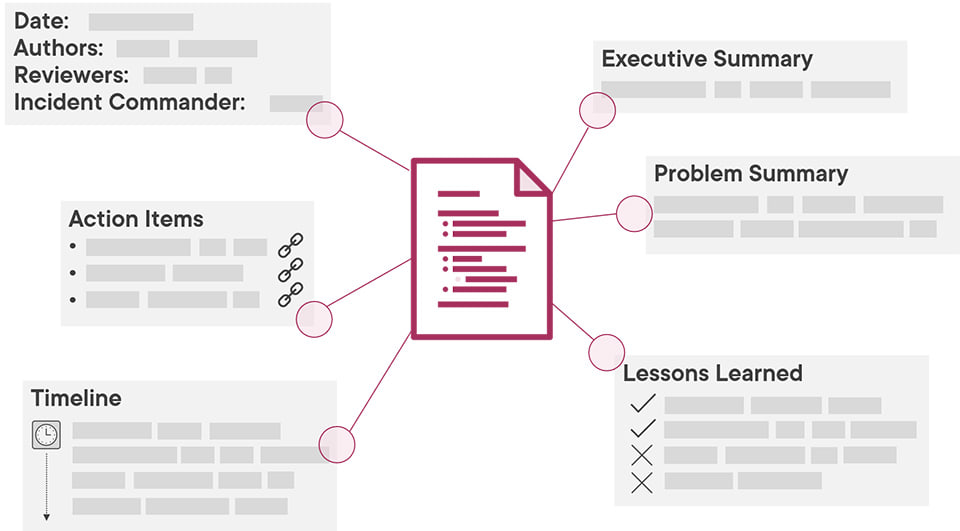
Postmortems are a great practice for turning incidents into a learning process. The goal is to prevent this incident or similar incidents happening, and they go a long way to encouraging a blame-free culture.
SRE as a Path to DevOps
SRE is much more proscriptive than DevOps which is another reason why SRE is easier to adopt. Practices are clearly described and you can start by implementing just the ideas which will make the biggest impact. If your incidents are taking too long to resolve, then postmortems will help you understand why. If your ops team are weighed down with repetitive work, you can adopt a toil limit. If product quality is low and downtime is high, start with error budgets.
Many organizations evolve into a model where only critical services have a dedicated SRE team. Product teams can ask for SRE involvement when they need it, but the goal is for the SREs to bring tooling and practices so the dev team can run the product themselves. That sounds a lot like DevOps, and it’s valid to have a mix of the two approaches as your end-goal.
Digital transformations which take a staged approach are easier to implement and it’s easier to assess their impact. Bringing on board some SREs and transitioning your ops teams to SRE is a great start; then you can have roving SREs embedded with product teams to help them become self-sufficient; finally leaving dedicated SRE teams for core products and infrastructure.